
Software Entwicklung
Intelligente Pipelines: Die Evolution der Continuous Integration mit Machine Learning

In den letzten Jahren haben DevOps-Praktiken die Softwareentwicklung revolutioniert, indem sie Automatisierung, Zusammenarbeit und schnellere Release-Zyklen fördern. Die Continuous Integration (CI) ist zu einem grundlegenden Pfeiler geworden, der die kontinuierliche Integration von Code und die rechtzeitige Erkennung von Fehlern ermöglicht.
Allerdings zeigen traditionelle CI/CD-Pipelines mit zunehmender Komplexität der Systeme und wachsender Datenmenge Grenzen in Bezug auf Vorhersage und Optimierung. In diesem Kontext entstehen die "intelligenten Pipelines": CI/CD-Arbeitsabläufe, die durch Machine Learning (ML)-Algorithmen bereichert werden, welche prädiktive und adaptive Fähigkeiten in den Softwarelebenszyklus einführen.
Was ist eine Traditionelle CI/CD-Pipeline
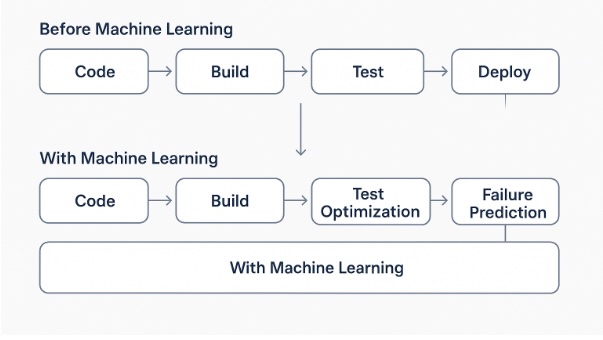
Eine traditionelle CI/CD-Pipeline automatisiert die Phasen des Builds, Tests und Deployments von Software. Tools wie GitLab CI, Jenkins und GitHub Actions orchestrieren diese Prozesse und stellen sicher, dass jede Codeänderung konsistent getestet und verteilt wird.
Diese Pipelines operieren allerdings hauptsächlich auf deterministischen Logiken und statischen Regeln. Sie besitzen nicht die Fähigkeit, aus historischen Daten zu lernen oder sich dynamisch an neue Bedingungen anzupassen, was ihre Effektivität in komplexen und sich schnell entwickelnden Umgebungen einschränkt.
Wenn CI auf Machine Learning trifft
Die Integration von Machine Learning in CI/CD-Pipelines ebnet den Weg für einen "intelligenten" oder datengetriebenen Ansatz. Durch die Analyse der während der Entwicklungsprozesse generierten Daten ist es möglich:
- Vorhersage der Buildzeiten: Nutzung von Regressionsmodellen zur Schätzung der Build-Dauer basierend auf Code- und Konfigurationsmerkmalen.
- Erkennung von Engpässen: Identifizierung von Prozessphasen, die wiederkehrend Verzögerungen verursachen.
- Optimierung der Tests (Test-Priorisierung): Auswahl und Anordnung der Tests basierend auf der Wahrscheinlichkeit der Fehlerkennung, zur Verringerung der Feedback-Zeit.
- Vermeidung von wiederkehrenden Fehlern: Analyse von Fehlermustern zur Vorhersage und Minderung ähnlicher Fehler in Zukunft.
Diese Fähigkeiten verwandeln diese Tools von reaktiven zu proaktiven Systemen und verbessern die Effizienz und Qualität der Software.
Praktische Beispiele für entwickelte CI/CD-Workflows
Die Einführung intelligenter Pipelines ist bereits in mehreren Organisationen Realität.
- Optimierung der Bereitstellungszeiten: Unternehmen wie Facebook nutzen ML, um dynamisch die relevantesten Tests auszuwählen und somit die Zeit für die Softwareveröffentlichung zu verkürzen.
- Integrierte ML-Modelle zur Fehlerprognose: Einige Unternehmen implementieren Modelle, die Codeänderungen analysieren, um die Wahrscheinlichkeit von Build-Fehlern vorherzusagen und präventive Maßnahmen zu ermöglichen.
- Automatische Log-Analyse zur proaktiven Diagnose: Fortschrittliche Tools analysieren die Build-Logs, um Anomalien zu identifizieren und Korrekturen vorzuschlagen, wodurch die Stabilität des Systems verbessert wird.
Diese Beispiele zeigen, wie künstliche Intelligenz die DevOps-Praktiken erheblich stärken kann.
Vorteile der ML-Integration in Pipelines
- Verkürzung der Feedback-Zeiten: Priorisierung der wichtigsten Tests ermöglicht Entwicklern schnellere Rückmeldungen zu ihren Änderungen.
- Bessere Build-Stabilität: Prädiktive Analysen helfen, potenzielle Probleme zu identifizieren und zu beheben, bevor sie auftreten.
- Intelligentere Release-Strategien: Ansätze wie Canary Deploy oder Progressive Delivery profitieren von prädiktiven Daten, um die Veröffentlichungen sicherer und effizienter zu gestalten.
- Kontinuierliche, datengetriebene Weiterentwicklung: Intelligente Pipelines lernen kontinuierlich aus den Daten und verfeinern im Laufe der Zeit ihre Vorhersagen und Optimierungen.
Diese Vorteile führen zu einer höheren Softwarequalität und einer Verringerung der Betriebskosten.
Nützliche Technologien und Frameworks
Zur Implementierung intelligenter Pipelines kann eine Kombination aus ML- und DevOps-Tools verwendet werden. Hier sind einige relevante Werkzeuge.
- ML-Tools, die mit Pipelines kompatibel sind: Bibliotheken wie TensorFlow, scikit-learn und PyCaret bieten Funktionen zur Erstellung von Vorhersagemodellen, die in Pipelines integriert werden können.
- Fortschrittliche DevOps-Tools, die Machine Learning integrieren: Plattformen wie Harness, CircleCI Insights und GitHub Copilot for CI bieten fortschrittliche Funktionen zur intelligenten Prozessautomatisierung.
Für eine umfassendere Ansicht zur Strukturierung von Automations- und Continuous Delivery-Pipelines für Machine Learning Systeme ist es nützlich, die technische Anleitung von Google Cloud zu MLOps zu konsultieren, die Best Practices, Architekturen und Betriebsmodelle für die ML-Integration in komplexe DevOps-Umgebungen beschreibt.
Die Wahl der Werkzeuge hängt von den spezifischen Projektanforderungen und der bestehenden Infrastruktur ab.
Wie Astrorei diese Evolution Annimmt
Astrorei positioniert sich als fortschrittlicher Technologie-Partner, der fortschrittliche DevOps-Lösungen bietet, welche Machine Learning integrieren, um die CI/CD-Prozesse zu optimieren. Dank eines Expertenteams und einem auf Innovation ausgerichteten Ansatz sind wir in der Lage, maßgeschneiderte, datengetriebene Automatisierung zu entwerfen und zu implementieren, die auf die spezifischen Bedürfnisse jedes Kunden zugeschnitten ist.
Kritische Punkte und Überlegungen
Trotz der zahlreichen Vorteile bringt die Einführung intelligenter Pipelines einige Herausforderungen mit sich:
- Datenqualität: ML-Modelle erfordern präzise und repräsentative Daten, um zuverlässige Vorhersagen zu treffen.
- Overfitting: Es besteht das Risiko, dass sich Modelle zu stark an historische Daten anpassen und ihre Vorhersagekraft auf neue Szenarien verlieren.
- Komplexität der Einrichtung: Die Integration erfordert spezifische Kenntnisse und eine sorgfältige Planung.
Um diese Herausforderungen zu bewältigen, ist ein schrittweises Vorgehen ratsam, das mit Pilotprojekten beginnt und Experten aus diesen spezifischen Bereichen einbezieht.
Fazit
Intelligente Pipelines stellen einen signifikanten Fortschritt in den DevOps-Praktiken dar, indem sie prädiktive und adaptive Fähigkeiten einführen, die Effizienz und Softwarequalität verbessern. Durch die Integration von Machine Learning in die CI/CD-Prozesse können Unternehmen Probleme vorhersehen, Ressourcen optimieren und Release-Zyklen beschleunigen.
Astrorei ist bereit, Sie auf diesem Innovationspfad zu begleiten.
Ob Sie nach einem Technologiepartner suchen, um Ihre DevOps-Prozesse zu innovieren, oder ein Entwickler sind, der neugierig ist, an fortschrittlichen Projekten zu arbeiten, die KI und Automatisierung integrieren - bei Astrorei finden Sie in einem inspirierenden und zukunftsorientierten Umfeld.
FAQs - Häufig gestellte Fragen
Wie wird die steigende Komplexität der CI/CD-Pipelines mit der Einführung von Machine Learning bewältigt?
Die Integration von Machine Learning in CI/CD-Pipelines bringt neue Herausforderungen mit sich, wie die Verwaltung nicht-deterministischer Modelle und die Notwendigkeit, die Modellleistung in Produktion kontinuierlich zu überwachen. Um diese Komplexitäten zu bewältigen, ist es entscheidend, MLOps-Praktiken zu implementieren, die Folgendes umfassen:
- Versionsverwaltung von Modellen: Verwendung von Tools wie MLflow oder DVC, um verschiedene Modellversionen und zugehörige Daten zu verfolgen.
- Kontinuierliches Monitoring: Implementierung von Überwachungssystemen, um Verschiebungen in Daten oder Leistung des Modells zu erkennen.
- Automatisierung des Retraining: Konfiguration von Pipelines, die Modelle bei Leistungsabfall automatisch neu schulen können.
Diese Praktiken helfen, die Pipelines skalierbar und zuverlässig zu halten, selbst mit wachsender Komplexität durch ML.
Was sind die Hauptherausforderungen bei der Integration von Machine Learning in bestehende CI/CD-Pipelines?
Die Hauptherausforderungen umfassen:
- Verwaltung der Abhängigkeiten: ML-Modelle hängen oft von spezifischen Versionen von Bibliotheken und Umgebungen ab, was die Abhängigkeitsverwaltung komplex macht.
- Rechenanforderungen: Das Training und die Inferenz von Modellen können erhebliche Rechenressourcen erfordern, was die Build- und Deployment-Zeiten beeinflusst.
- Testen und Validieren: Das Validieren von ML-Modellen ist komplexer als bei traditioneller Software, da die Leistung je nach Daten variieren kann.
Diese Herausforderungen erfordern besondere Aufmerksamkeit bei der Pipeline-Gestaltung sowie den Einsatz spezieller ML-Tools und -Praktiken.
Wie kann die Sicherheit der CI/CD-Pipelines gewährleistet werden, die Machine-Learning-Modelle integrieren?
Die Sicherheit der CI/CD-Pipelines mit ML kann durch folgende Maßnahmen gewährleistet werden:
- Zugangskontrolle: Implementierung strenger Zugriffspolitiken, um zu begrenzen, wer Modelle oder Daten ändern kann.
- Validierung der Artefakte: Überprüfung der Integrität von Modellen und Daten vor der Bereitstellung, um die Einführung von bösartigem Code oder Daten zu verhindern.
- Überwachung der Abhängigkeiten: Nutzung von Analysetools für Abhängigkeiten, um bekannte Schwachstellen in verwendeten Bibliotheken zu identifizieren und zu entschärfen.
Diese Maßnahmen tragen zur Sicherung des gesamten Modells-Lebenszyklus und zur Aufrechterhaltung des Vertrauens in das System bei.
Können vortrainierte Machine-Learning-Modelle in CI/CD-Pipelines integriert werden?
Ja, es ist möglich, vortrainierte Modelle in CI/CD-Pipelines zu integrieren. Allerdings ist Folgendes zu berücksichtigen:
- Kompatibilität: Sicherstellen, dass das Modell mit der Produktionsumgebung kompatibel ist.
- Anpassung: Prüfen, ob das vortrainierte Modell ein Fine-Tuning benötigt, um sich an die spezifischen Anwendungsdaten anzupassen.
- Lizenzen: Überprüfung der mit dem Modell verbundenen Lizenzen, um die rechtliche Konformität sicherzustellen.
Die Integration von vortrainierten Modellen kann die Entwicklung beschleunigen, erfordert jedoch eine sorgfältige Bewertung, um Effektivität und Compliance zu gewährleisten.
Wie kann die Effektivität von Machine-Learning-Modellen in der Produktion überwacht werden?
Die Überwachung der Effektivität von Modellen in der Produktion ist entscheidend für die Sicherstellung optimaler Leistungen. Zu den gängigen Praktiken gehören:
- Verfolgung von Metriken: Erfassung von Metriken wie Genauigkeit, Präzision, Rückruf usw., um die Modellleistung zu bewerten.
- Erkennung von Drift: Identifizierung von Änderungen in den Eingabedaten, die die Modellleistung beeinflussen könnten.
- Feedbackschleife: Implementierung von Mechanismen zur Sammlung von Feedback von Nutzern oder nachgelagerten Systemen, um das Modell kontinuierlich zu verbessern.
Der Einsatz von Monitoring- und Alarmierungstools hilft, die Modelle langfristig effektiv zu halten.

Bajram Hushi
Das könnte Sie interessieren
Sprechen Sie mit unseren Experten
BEGINNEN SIE IHRE KOSTENLOSE PLANUNG
Erzählen Sie uns von Ihrem Projekt, wir geben Ihnen eine klare Roadmap.
Ein Experte wird Sie innerhalb von 24 Stunden mit einer ersten kostenlosen Einschätzung kontaktieren.
